
Noise-canceling headphones are getting smarter, thanks to AI
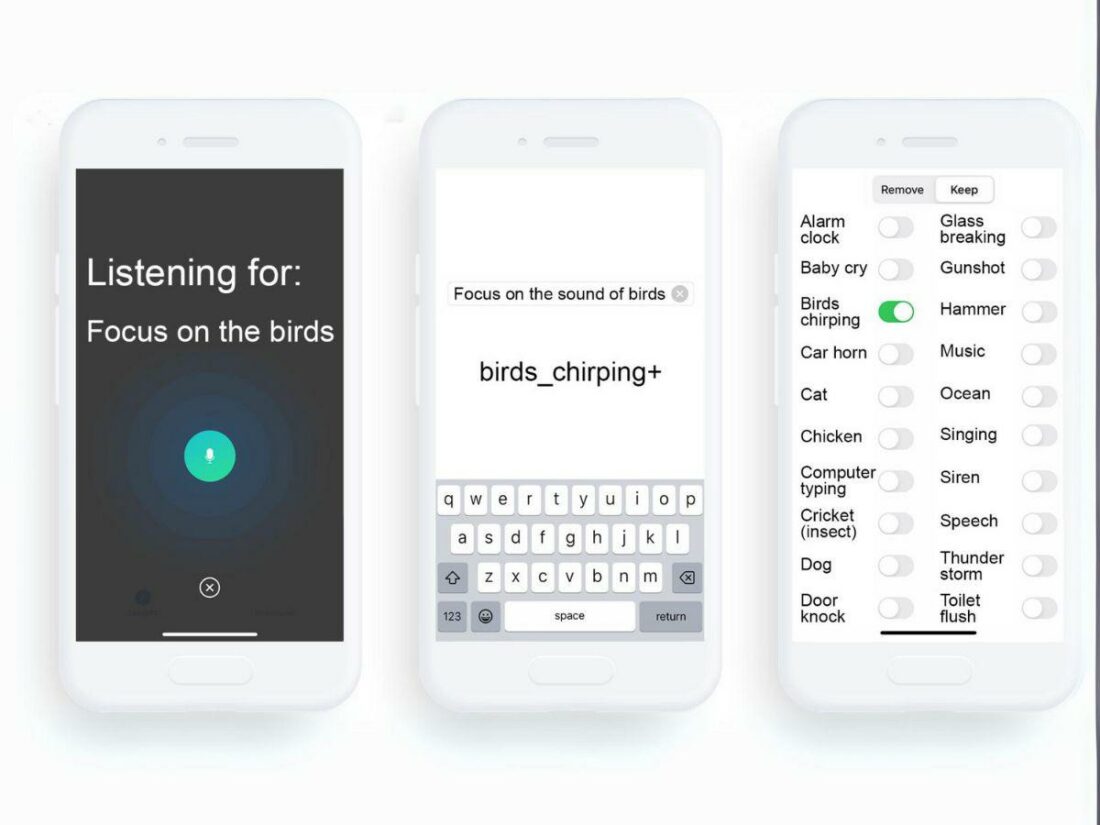
The University of Washington’s research team has unveiled a groundbreaking AI technology in headphones, named “Semantic Hearing.” This technology uses deep-learning algorithms to let users pick the specific sounds they want to hear while canceling all other noises.
For instance, when using a vacuum cleaner, these headphones can be set to allow the sound of a door knock to pass through while silencing the vacuum’s noise. This way, you stay alert to visitors without the distraction of unwanted sounds.

What is the New Noise-Canceling Technology All About?
The new AI noise-canceling headphone technology addresses a key issue with current noise-canceling systems: the lack of selectivity in what sounds are blocked out.
Traditional noise-canceling headphones indiscriminately suppress all environmental noise. This can be problematic in situations where certain sounds, like alarms or voices, are important for safety or interaction.
In contrast, Semantic hearing enables users to choose specific sounds they wish to hear, while other background noises are canceled out. This includes crucial sounds like alarms, voices, or sirens.
Imagine a pedestrian navigating a busy city street while wearing noise-canceling headphones.
Traditional headphones would block out all sounds, including potentially dangerous ones like car horns or emergency vehicle sirens, which are crucial for pedestrian safety.

With semantic hearing technology, the user can choose to allow these specific sounds to filter through. This ensures they remain alert to potential hazards while still enjoying a noise-free experience.
How Does It Work?
Semantic hearing combines deep-learning algorithms and smartphone processing to selectively filter environmental sounds.
The technical operation of this system is intricate. It repurposes the noise-canceling microphones in the headphones to detect environmental sounds. These are then relayed to a neural network running on the smartphone. This neural network then identifies and adjusts the sounds in real time according to the user’s settings.
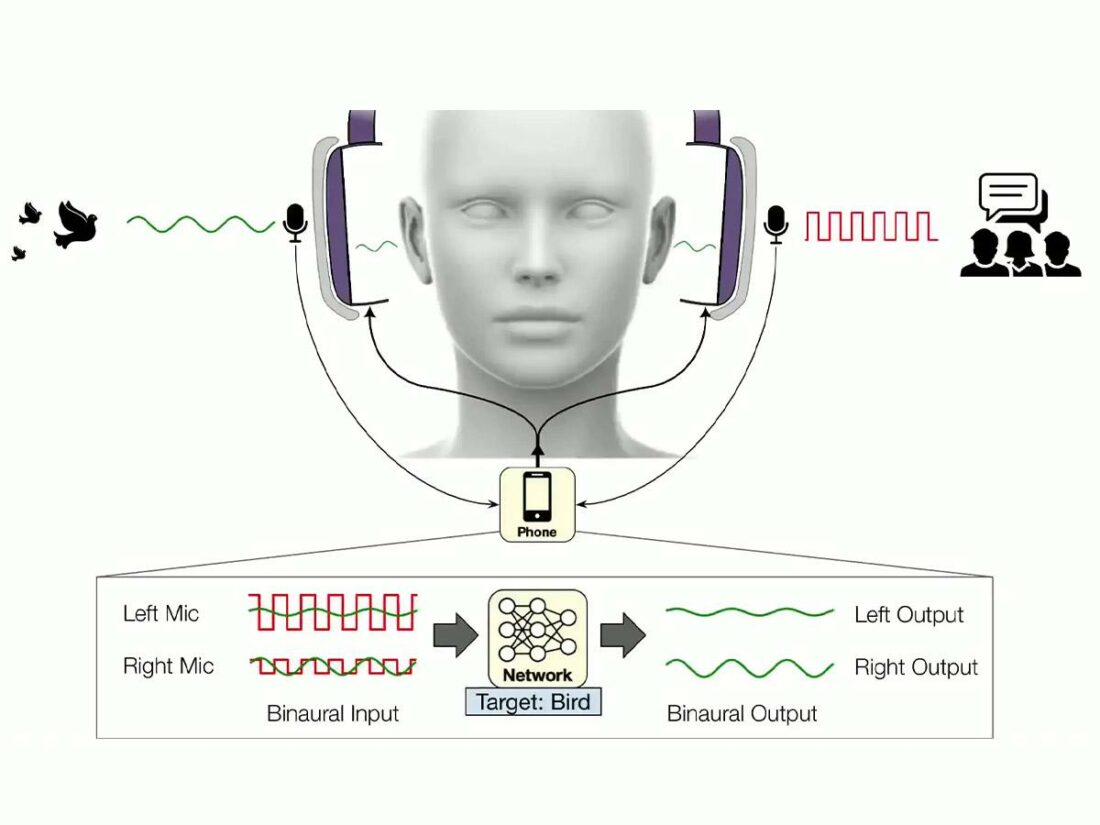
The main challenge for the researchers was to ensure the speed and accuracy of this technology.
However, they solved this by streaming the ambient sound through a connected smartphone. This system allows real-time processing for sound synchronization and preserves the required delays to maintain spatial cues for sounds coming from different directions and distances.
Challenges and Limitations
While promising, the technology is still in its prototype stages. It also currently struggles with differentiating similar sound profiles.
For example, it had difficulty separating human speech from music. This issue was particularly pronounced with genres like rap music, which closely mimic speech patterns.
To overcome this, the research team aims to improve accuracy by training the AI with more diverse, real-world data. They believe that doing this will help the system differentiate between similar sounds.
Looking ahead, the team is hopeful about refining the technology for commercial use.