
We cover arguments that suggest headphones are better-suited in exhibiting certain characteristics of loudspeakers than loudspeakers themselves, as well as the other way round.

“A Deep Dive Into Harman Curves” Series Navigation:
Making Headphones Better Loudspeakers than Loudspeakers
Headphones have several characteristics distinct from loudspeakers. One is the absence of room effects, which is a double-edged sword. On one hand, it means that speaker boundary interference response, which can massively distort midbass is absent. Yet, room reflections that resemble the direct sound of the speaker may actually help in generating a sense of enjoyable spaciousness outside of the head.
HRTF Correction
Nonetheless, headphones also offer a compact setup, reduce noise leakage, and can offer low bass extension much more affordably than speakers (albeit without full-body tactility). Bearing this in mind, numerous attempts have been made to exploit the benefits of headphones while improving both tonal and spatial accuracy through using sophisticated processing to yield the net response of a speaker playing in a listening room plus the listener’s Head Related Transfer Function (HRTF).
Programmes that do so include the BACCH-hp from Princeton’s 3D Audio and Applied Acoustics Lab, Darin Fong Out of Your Head, the Smyth Realiser, Creative Super X-fi, Waves NX and Genelec Aural ID. They differ in the details.
Some use a HRTF (without a loudspeaker or room as intermediary) generated by calculation, like Genelec; others, like Smyth and Darin Fong, use actual measurements of loudspeaker setups with the listener’s own ears and a dummy head respectively.
After all, measuring the HRTF of a known external sound source and processing the headphones to replicate it readily achieves externalization. More involved systems like the BACCH-hp add head tracking for dynamic cues, at the cost of complexity and finances.
Crossfeed
While HRTF correction deals more in ensuring played back signals reaching the eardrum more closely mimic that of an external sound source, crossfeed attempts to retrieve interaural cues that may emerge from the crosstalk of speakers.
Crossfeed refers to the introduction of crosstalk: where a low-level signal from the right channel is played on the left, and vice versa. The most famous example of it is the Meier crossfeed.
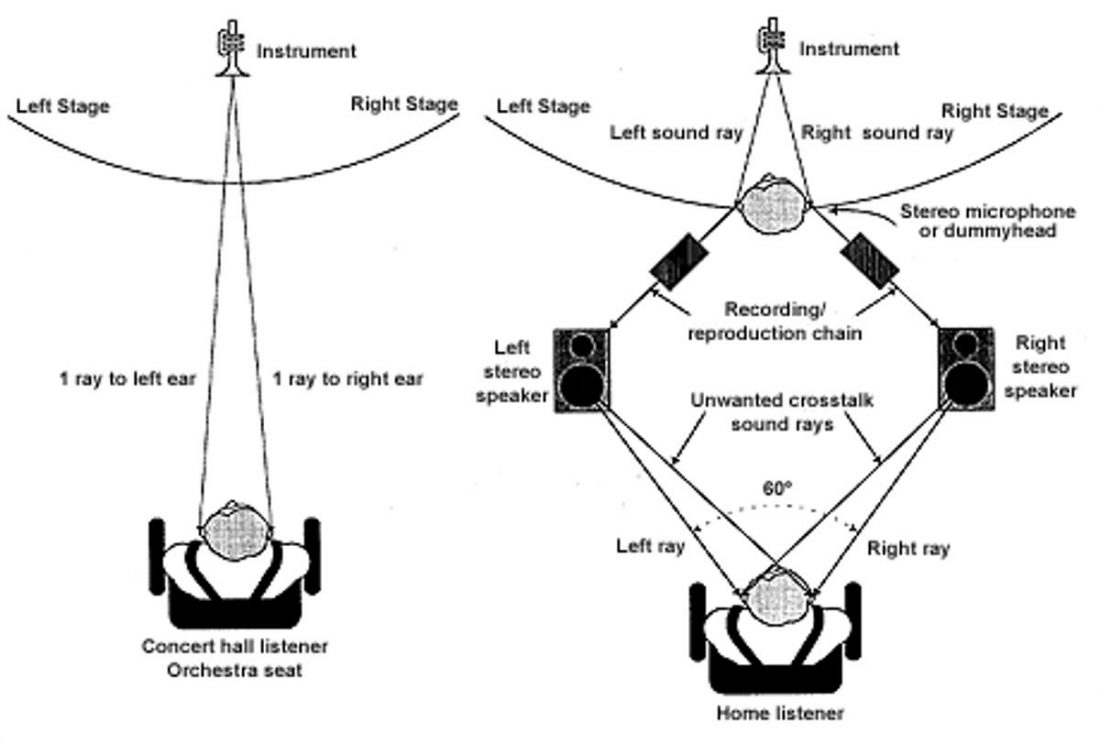
This is where things get really tricky and recording-dependent. This is because there are credible arguments for the generation of plausible interaural cues through the playback method of stereo loudspeakers, where the output from both speakers mix with each other; the sound from the left speaker can reach both ears and vice versa. This creates ITD cues below 700Hz that establish a sense of left-right direction to sound around the arc of the stereo triangle.
Yet, this same playback method can also obscure interaural cues that were originally embedded in the recording, argue other researchers (see “Crosstalk Cancellation”). The intention of the sound engineers behind each recording, and their choices are crucial toward determining if crosstalk is a foe or friend. The image above shows a simplified representation of crosstalk. It is correct, but clearly from a source that deems crosstalk an enemy more of the time.
Making Speakers Better Headphones than Headphones
Crosstalk Cancellation
The simplest form of crosstalk is by putting a mattress or some other form of absorbent barrier between two speakers.
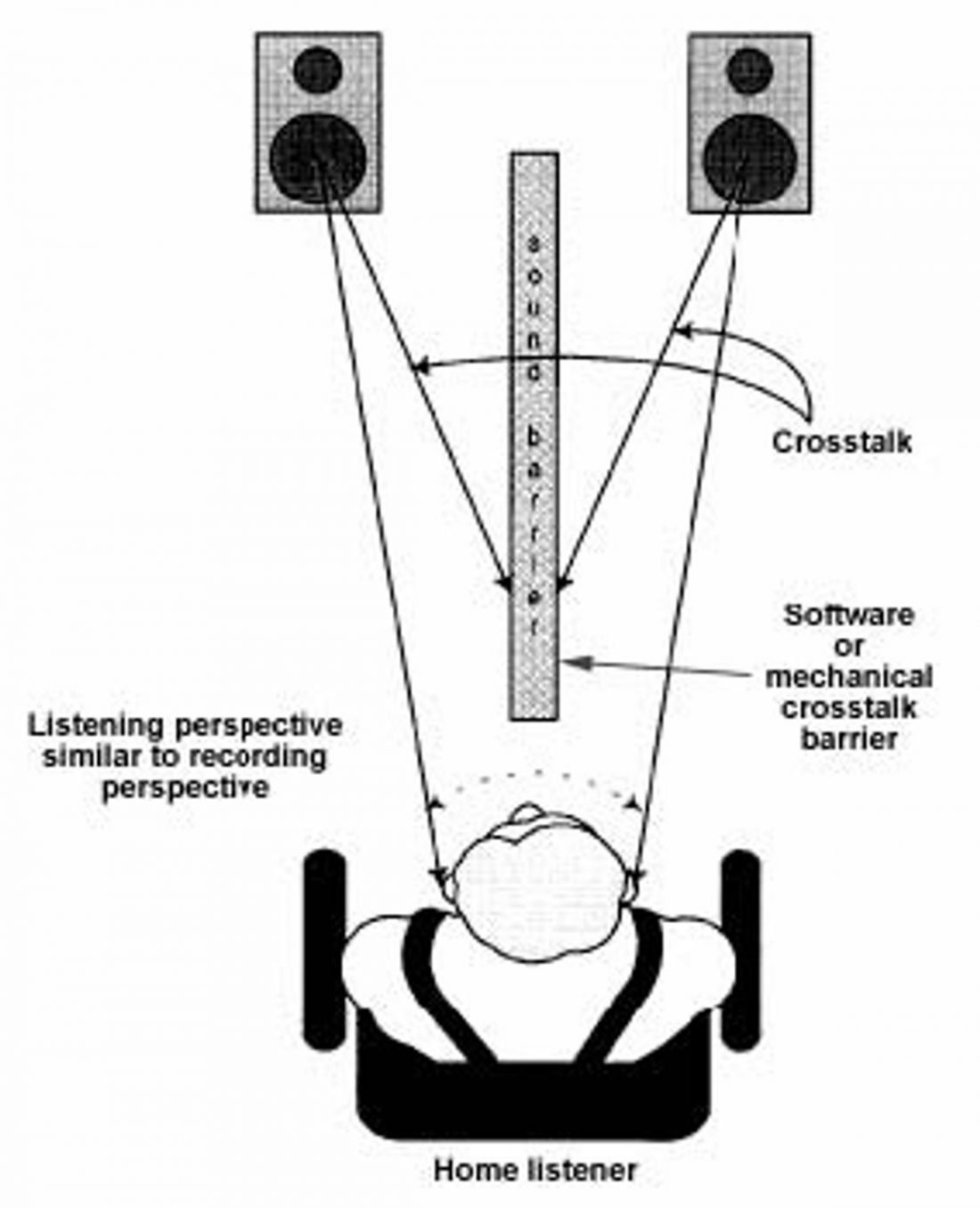
Crosstalk cancellation is the antithesis of crossfeed. It is the removal of crosstalk on speakers, to mimic the signature property of headphones – no crosstalk. Sound from each channel does not mix with any other. The mattress acts as a physical absorber to this effect, but electronics can do it as well. Arguably, having a mattress in front of the listening position might strike up more conversation, though.
A free, pioneering example is Ambiophonics, which relies on manual calibration by the listener, but lacks head tracking and HRTF individualization through ear measurements.
An early hardware example was the Carver Sonic Holography DSP box, released in the 1980s. However, the problem with the Carver was that it lacked the computational power to cancel crosstalk recursively, which is necessary for the technique to work more consistently, as Ralph Glasgal, another leading expert explains:
When a signal from the left speaker undesirably reaches the right ear, it must be cancelled at that ear by an inverted, perfectly delayed, slightly lower level replica from the right speaker. But this cancellation signal will also reach the left ear and so it must also be cancelled (2nd order cancellation) by a properly conditioned signal from the left speaker, which signal then also reaches the right ear requiring another round (3rd order) of cancellation, and so on.
For a greater tolerance for non-ideal speakers, to avoid frequency response errors, and to enlarge the listening area, this recursive “ping-pong” correction needs to be carried out to inaudibility.
This assumes that certain microphone configurations and panning have interaural cues. Recall that the playback method of stereo theoretically generates interaural cues up to around 700Hz, but not higher up.
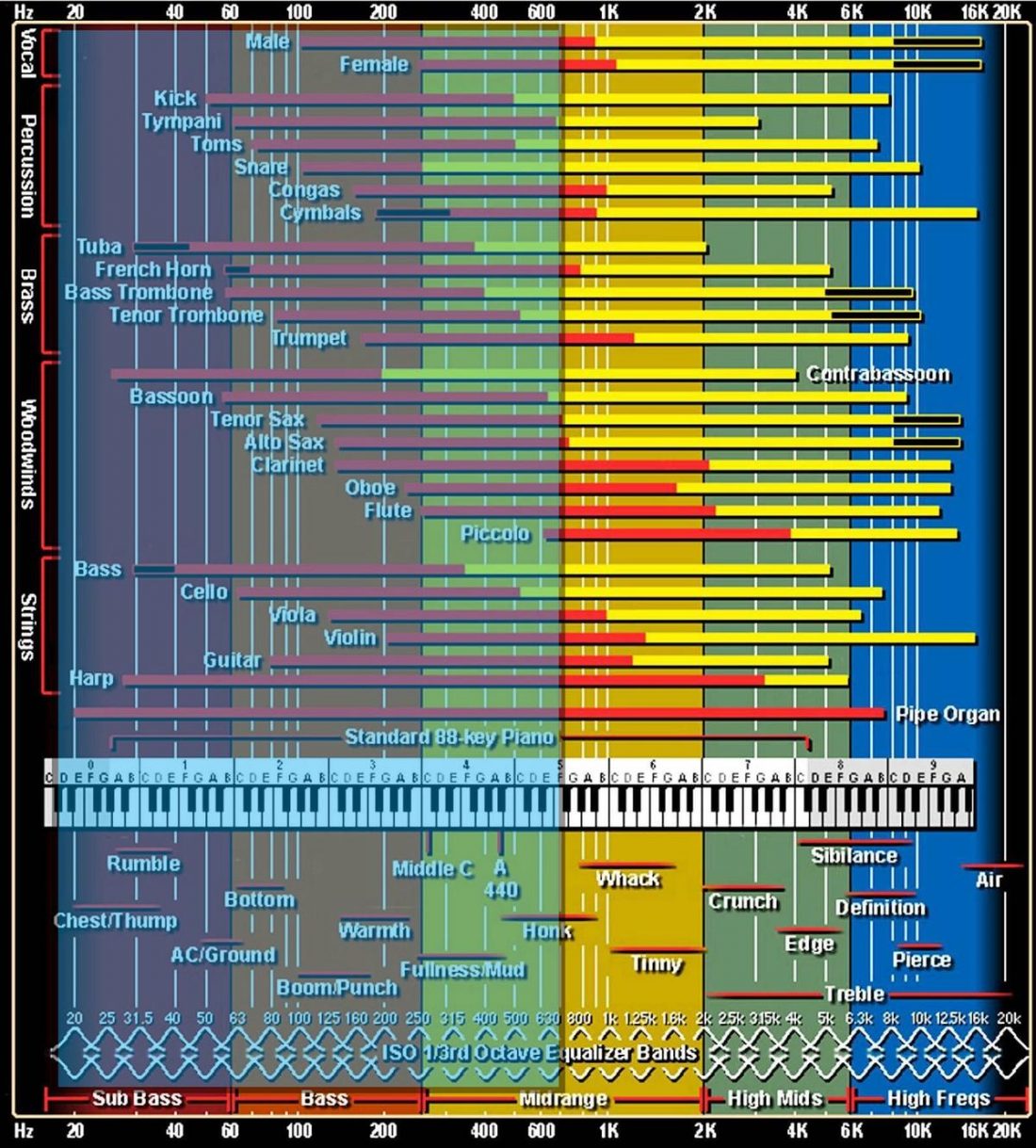
The blue overlay (added by the author) in the above diagram shows the instruments that generate sound below 700Hz (which is to be taken as an approximation that can vary). The orange bars represent the fundamental, while yellow represents the harmonics. As this diagram has often been shared online, you may have seen it before.
It shows us the range of frequencies music and musical instruments typically cover, as well as some common adjectives used to describe them. The boundaries are, of course, more of a transitional range rather than a sudden change, and different specimens of the same instrument would subtly differ.
Crosstalk cancellation proponents would argue the generation of cues by the playback technique of stereo distorts cues both above and below 700Hz already embedded in the recording.
Although below 700Hz does not seem like a broad range, it covers most of the fundamental tones numerous instruments can output, as well as some of their harmonics. This includes the tenor sax, kick and snare drums, the cello and the human voice.
Nonetheless, crosstalk cancellation promises a wider bandwidth over which interaural cues are retrieved, potentially increasing 3D imaging. Another leading expert on the subject, Prof. Edgar Choueiri from Princeton argues:
Any properly recorded stereo album has ITD and ILD cues embedded in the recording, and it is these cues that present the normal stereo image. If you record using Spaced Omnis, for example, these will capture a strong ITD signal, and will capture, for example, the reverb of the recording environment.
ORTF recordings use cardioid mikes, which tend to emphasize the ILD cues, since they are typically too close together for a strong ITD signal. So most acoustically recorded recordings will produce an extraordinarily impressive and satisfying 3D spatial image. So you will hear a very strong 3D image, and not the normal stereo image locked to the speakers. It just won’t necessarily be spatially accurate.
A technical FAQ by Prof. Choueiri’s laboratory in Princeton adds:
Stereophonic recordings fall on a spectrum ranging from recordings that highly preserve natural ILD and ITD cues (these include most well-made recordings of “acoustic music” such as most classical and jazz music recordings) to recordings that contain artificially constructed sounds with extreme and unnatural ILD and ITD cues (such as the pan-potted sounds on recordings from the early days of stereo).
For stereo recordings that are at or near the first end of this spectrum, BACCH™ 3D Sound offers the same uncanny 3D realism as for binaural recordings. At the other end of the spectrum, the sound image would be an artificial one and the presence of extreme ILD and ITD values would, not surprisingly, lead to often spectacular sound images…
Regardless of complete spatial accuracy, the mere fact that sound is externalized and 3D means it is necessarily more realistic than flat, internalized sound constricted to around our heads. It can be combined with individualized HRTF correction and head-tracking to cover all conceivable localization cues, including the part of sound localization pertaining to accurate frequency response. The results of this meticulous setup?
Put simply, evidence suggests a crude hierarchy appears for potential/theoretical fidelity:
- Binaural loudspeaker playback: Pinna fully illuminated with preservation or even extraction of binaural cues through crosstalk cancellation, aided by head-tracking and HRTF individualization)
- Binaural headphones: Because of the possibility of HRTF individualization and good headphone design to minimize the effects of bad pinna illumination,
- Stereo speakers: No inherent problems with pinna illumination, thereby allowing externalization),
- Stereo headphones: Pinna illumination problems cause head internalization of sound.
Conclusion
This detailed explanation of a few technologies builds up into the crescendo that is Part 3.
Part 3 covers the products and target curves that have already been released onto the market. It critiques and compares each of them to the Harman curves, thus fulfilling the purpose of this series: to evaluate the assumptions and evidence for the Harman curves, compared to alternatives.
Pin this image to save article
